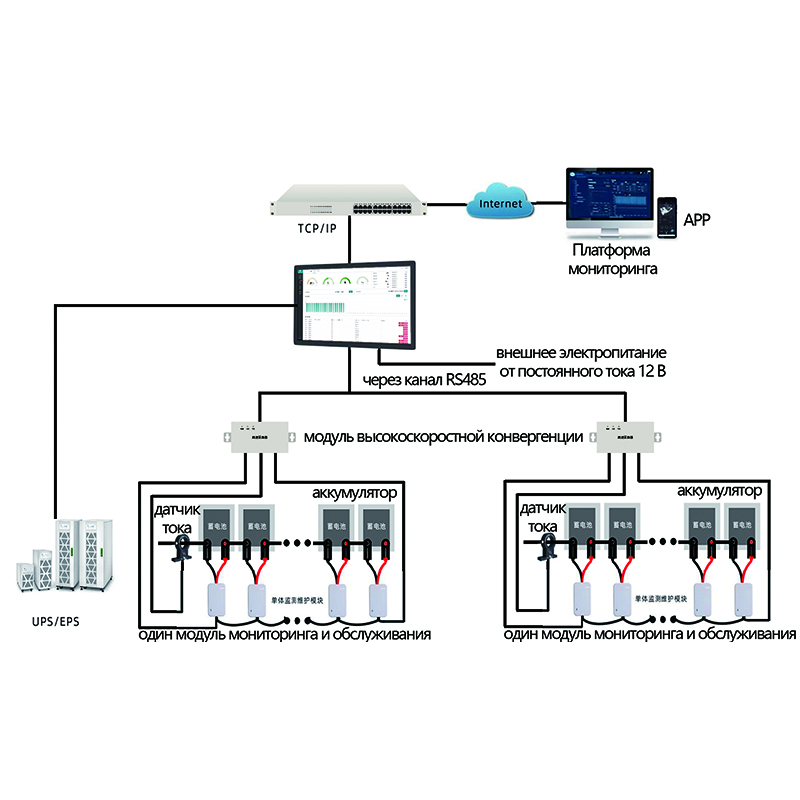
Многие начинающие специалисты считают мониторинг дата-центров простым сбором данных и анализом графиков загрузки ЦП. Это, конечно, часть работы. Но на практике это гораздо сложнее и, что важнее, требует глубокого понимания процессов и потенциальных слабых мест инфраструктуры. Недавно столкнулся с ситуацией, когда кажущийся незначительный рост задержек привел к серьезному отказу в работе критически важного сервиса. Именно тогда я осознал, что мониторинг – это не просто инструмент контроля, а способ прогнозирования и предотвращения проблем.
Итак, что же подразумевается под эффективным мониторингом? Это комплексный подход, включающий в себя несколько уровней: от аппаратного мониторинга (серверы, сетевое оборудование, источники питания, системы охлаждения) до программного (операционные системы, приложения, базы данных, сетевой трафик). Простое отслеживание температуры и загрузки ЦП – это лишь верхушка айсберга. Важно понимать взаимосвязь этих параметров и уметь выявлять аномалии, которые могут указывать на надвигающуюся проблему. Например, постепенный рост задержек в сети может быть вызван не просто перегрузкой, а, например, неисправностью одного из сетевых интерфейсов или проблематикой с маршрутизацией.
Многие компании используют готовые решения для мониторинга, но часто они недостаточно гибкие и не позволяют настроить специфические метрики, которые важны именно для их инфраструктуры. Это как пытаться управлять самолетом, используя только компас – может и получится долететь, но это очень рискованно. Поэтому важно понимать, какие метрики критичны для вашего бизнеса и как они влияют на производительность сервисов.
Какие метрики стоит отслеживать в первую очередь? Помимо очевидных показателей, таких как загрузка ЦП, использование оперативной памяти и дискового пространства, важно обращать внимание на следующие: время отклика приложений, пропускная способность сети, количество ошибок, уровень логирования, состояние источников питания и системы охлаждения. Не стоит забывать и о метриках безопасности, таких как количество попыток несанкционированного доступа и наличие уязвимостей в системе.
Особенно важно отслеживать метрики, специфичные для ваших приложений. Например, для базы данных это могут быть время выполнения запросов, количество соединений и использование ресурсов. А для веб-сервера – количество запросов, время загрузки страниц и количество ошибок. В нашей практике, часто оказывается, что самая большая проблема возникает не из-за недостатка ресурсов, а из-за неоптимизированного кода или неправильной настройки приложений. Это, конечно, не задача мониторинга, но хорошая система мониторинга может выявить эти проблемы на ранней стадии, позволяя их устранить до того, как они приведут к серьезным сбоям.
Рынок инструментов для мониторинга дата-центров сейчас очень насыщен. Можно выбрать как open-source решения (Zabbix, Nagios, Prometheus), так и коммерческие (Datadog, New Relic, SolarWinds). Выбор зависит от бюджета, требований к функциональности и квалификации персонала. Open-source решения позволяют добиться большей гибкости и контроля над системой, но требуют больше времени и усилий для настройки и обслуживания. Коммерческие решения, как правило, более просты в использовании и предлагают широкий спектр функций, но стоят дороже.
В ООО Тяньцзинь Жуйлитун Технолоджи мы часто рекомендуем своим клиентам комбинировать несколько инструментов для мониторинга, чтобы получить максимально полную картину происходящего. Например, можно использовать open-source решение для мониторинга аппаратного обеспечения и коммерческое решение для мониторинга приложений. Главное – чтобы эти инструменты были интегрированы между собой и позволяли получать консолидированную информацию о состоянии всей инфраструктуры.
Однажды мы столкнулись с проблемой периодических 'зависаний' одного из наших ключевых приложений. Изначально мы подозревали проблемы с сервером, на котором оно работало. Но после тщательного анализа данных мониторинга выяснилось, что проблема заключалась в перегрузке сети между сервером и базой данных. Оказывается, что один из сетевых кабелей был поврежден, что приводило к периодической потере пакетов данных и, как следствие, к 'зависаниям' приложения. После замены кабеля проблема была решена. Этот случай показал нам, насколько важно не ограничиваться мониторингом отдельных компонентов, а анализировать взаимосвязи между ними.
Ключевой момент здесь – это не просто наличие инструментов, а умение правильно интерпретировать данные и выявлять закономерности. Это требует опыта и знаний в области сетевых технологий, операционных систем и приложений. Наша команда регулярно проводит тренинги для персонала, чтобы повысить их квалификацию и научить их эффективно использовать инструменты мониторинга.
Технологии мониторинга дата-центров постоянно развиваются. В последнее время все большую популярность набирают решения на основе искусственного интеллекта и машинного обучения. Эти решения позволяют не только отслеживать текущее состояние инфраструктуры, но и прогнозировать потенциальные проблемы на основе исторических данных. Например, можно настроить систему, которая будет автоматически обнаруживать аномальное поведение и предупреждать об этом администраторов. Это может значительно сократить время простоя и повысить надежность сервисов.
В будущем, я думаю, мы увидим еще более тесную интеграцию мониторинга с другими системами управления инфраструктурой, такими как автоматизация и оркестровка. Это позволит создавать более гибкие и адаптивные системы, которые смогут автоматически реагировать на изменения в нагрузке и оптимизировать использование ресурсов. А также, как компания ООО Тяньцзинь Жуйлитун Технолоджи, мы планируем развивать направление мониторинга с акцентом на возможности анализа данных и прогнозирования проблем, что позволит нашим клиентам более эффективно управлять своей инфраструктурой и снижать операционные расходы. Нам кажется это очень важным направлением.